
Solving a puzzle game the easy way
An android game I’ve been really enjoying lately is move from Nitako Brain Studios. It is a game with simple mechanics and extremely good puzzle design.
Game Mechanics
Their trailer shows off pretty much everything you need to know about it. If you don’t access to youtube then I’ll do my best to explain.
A board consists of an n by n square featuring n colored dots, n shaded squares whose colors match the dots and any number of blocking obstacles. Each move, you select one cardinal direction and swipe the screen in that direction. All dots move one square in that direction unless they are blocked by a wall, an obstacle, or another blocked dot.
Consider the following example:
Here is the initial state of the board

We swipe left to move the top and bottom dots one space to the left and producing this board

Next we swipe down moving the rightmost dot down

Finally we swipe left to align all dots with shaded square

For each board, the game tells you how many moves are in the optimal solution.
A Puzzle I Couldn’t Solve
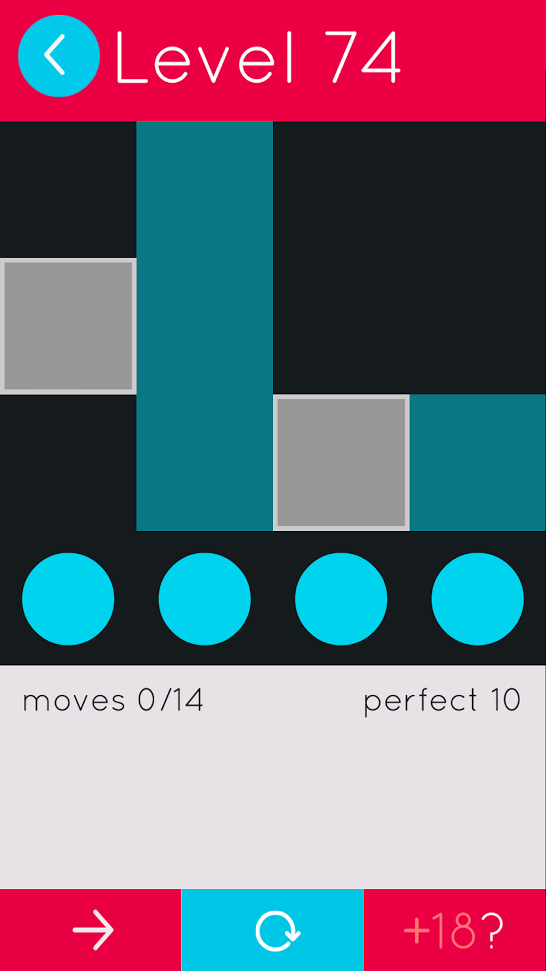
I had solved 99/100 of the 4x4, 1 color puzzles with the shortest possible solution but struggled on puzzle number 74. My shortest solution, URURDRURLLDU was two moves too long.
Trying to Brute Force on Paper
My strategy to solve the game was to work both forward and backward. Working forward it was easy to see that the first move must be up; all other moves have no effect. Working backward it was easy to see that the last move must be up as well. No state exists such that a left, right or down leads to the goal state. From there the options became far more numerous. I met in the middle believing we knew all states that could be reached after 4 moves and all states that could be reached after 6 moves. I then used heuristics to pairwise rule out all the options. I concluded that the board could be solved in at best 11 moves.
Solving the game in code
I decided to write some python to settle whether or not this puzzle could be completed in ten moves. My implementation has two parts.
- A python class that more or less implements the entire game
- A python main that tries possible move sequences to see if they cause victory.
I reused the python class with only minor modifications across my version of the solver. The class treated a board state as a 2D array of ints where 0’s represented empty space, -1’s represented unmoving blockers and 1’s represented dots. For puzzles featuring more than one color, number other than 1 can be used to specify the color of a dot/goal position. It had a function to do the action of swiping in each direction and not much else.
###V1 My first version of the program optimized for programmer time not runtime. There are at most 4^10 (roughly one million) possible move sequences. It isn’t that expensive to compute one move on the board. Lets just simulate each of the one million sequences and print the first successful solution we find.
The two interesting pieces of code were as follows.
1 def move_sequence(self, instructions, num_instructions):
2 for i in range(num_instructions):
3 todo = instructions % 4
4 instructions = instructions / 4
5 if todo == 0:
6 self.move_down()
7 elif todo == 1:
8 self.move_up()
9 elif todo == 2:
10 self.move_right()
11 else: # todo == 3
12 self.move_left()
The board class exposed a function that took an integer, treated it as a sequence of moves, and executed that sequence on its internal board.
1 num_moves = 10
2 for i in range(4**num_moves):
3 my_board.reset()
4 my_board.move_sequence(i, num_moves)
5 if my_board == goal_board:
6 print 'FOUND IT!'
7 my_board.move_sequence_str(i, num_moves)
8 break
The main function then called the move_sequence function on every integer in the valid range and then compared the result against the desired final board.
####The Good
- Very quick to write
- Potentially parallelizable?
####The Bad
- Slow
- 17 second runtime
- Tons of recomputed data
- The transitions from the starting state to each of the 4 following states were each calculated ~250,000 times.
- Doesn’t abandon fruitless paths
- Swiping down as a first move has no effect so it can’t possibly be the first move but this iteration of the program tries ~250k sequences that begin with swiping down.
- Needs to know how long the ideal solution is at compile time
###V2 This version of the program attempted to leverage the fact that early subsequences were being executed many times by using memoization. I also decided to return a list of solutions in case there were multiple.
1 def search(path, board, depth, max_depth, goal):
2 if depth == max_depth:
3 if board == goal:
4 return [path]
5 return []
6 else:
7 ret = []
8 for char, board in {'U': board.move_up(),
9 'D': board.move_down(),
10 'L': board.move_left(),
11 'R': board.move_right(),
12 }.iteritems():
13 if(board):
14 success = search(path + char, board, depth + 1, max_depth, goal)
15 if success:
16 ret += success
17 return ret
I made a minor change to my board class here to make the move_* functions return false if they failed to change the board state (not shown).
The above function then depth first explores a tree where every node holds the state of the board after the sequence of steps leading to it. The change to the board class made it easy to ignore fruitless subsequences. Whenever I encountered a move that didn’t change the board state, I stopped exploring that branch of the tree (line 13).
####The Good
- Much faster than V1
- 4 second runtime
- Relatively memory inexpensive - The memoization stored at most as many boards as the length of the solution at a given time.
####The Bad
- No sense of duplicate state
- Up then Down on the board resets initial state but this program still tries up to 4^8 sequences beginning with that sequence - none of which are viable
- Not only that but it computes those paths multiple times, once for each way of re-entering the starting state.
- Needs to know how long the ideal solution is at compile time
###V3 This version switched from depth first search to breadth first search. It is built on the idea that most states are reachable in many ways and we shouldn’t have to keep paying to do the same computations on those states.
1 # key, Board object
2 # val, string
3 # represtents all visited states and the shortest paths to them
4 boards = {}
5 boards[my_board] = ""
6
7 # a deque of (Board, str) tuples
8 to_search = deque()
9 to_search.append((my_board, ""))
10
11 while to_search:
12 (working_board, path) = to_search.popleft()
13 for char, board in {'U': working_board.move_up(),
14 'D': working_board.move_down(),
15 'L': working_board.move_left(),
16 'R': working_board.move_right(),
17 }.iteritems():
18 if board == goal_board:
19 print path + char + '\n'
20 elif board in boards:
21 pass
22 else:
23 boards[board] = path + char
24 to_search.append((board, path + char))
It maintains dict of all visited states and the shortest known path to them. Whenever a state is computed, the algorithm checks if it is new and ignores if it is not. In the case of the board in question, only ~500 states were reachable in any number of moves.
####The Good
- Much faster than V2
- 0.2 second runtime
- Does not need to be told how long the ideal solution is
####The Bad
- Requires more memory
- I forgot to tell it when to stop other than when it has reached all states
Result and Analysis
It turns out there were two solutions.
- UURDULLDRU
- ULUULDRDDU
It is clear to me now that a state centric approach with caching of intermediate results is the correct method. V1 computed as many as 4 million transitions between states. V3 only did work on each state once so it computed at most ~2000 transitions.
Where We Went Wrong on Paper
- Working backward was harder than it seemed. One move to enter a state may mean many possible preceding states.
- Seemingly implausible states may be easier to get into than anticipated.
Open Questions
- How was this puzzle generated?
- More generally, how were the 1000+ puzzles in the game generated
- Given the set of solutions to a puzzle, is it possible to reconstruct the
initial board?
- What additional information helps (i.e. board size, distribution of colors…)
- What is the board/goal pair with the longest possible solution at each board
size?
- In the case of puzzle 74, there is a state that cannot be reached in fewer than 19 moves!
- The two solutions to this puzzle are nearly anagrams. The first has an extra R and the second has an extra D. How far can solutions to the same board be from each other in terms of distribution of moves?